Qlikview Enterprise Edition Server versió 12.50
SO: Windows Server 2019 / RAM: 32GB / 8 CPU de 2,60 GHz
Qlikview Extranet Server versió 12.50
SO: Windows Server 2019 / RAM: 32GB / 8 CPU de 2,60 GHz
Qlikview Internet Acces Server versió 12.50
SO: Windows Server 2019 / RAM: 32GB / 8 CPU de 2,60 GHz
QlikSense Enterprise Server versió de Maig de 2022
SO: Windows Server 2019 / RAM: 64GB / 8 CPU de 2,60 GHz
Disposem de tres entorns: desenvolupament, test i productiu.
Geoanalytics Server versió Agost 2022
S'utilitzarà la cartografia generada per la pròpia Diputació de Barcelona.
Nprinting versió novembre 2019
Pentaho Server versió 9.2 Community
SO: Windows Server 2016 / RAM: 16GB/ 4 CPU de 2,60 GHz
Pentaho User Console
S'utilitza per a programa y executar els processos de l'entorn de productiu.
Qlikview Desktop versió 12.50
QlikSense Desktop versió Maig 2022
S'espera que els proveïdors treballin amb llicència pròpia.
Pentaho Data Integration versió 9.2 (versió CE)
Cal configurar Idioma-locale = es (ES).
Aplicacions accés als portal web Qlikview i Qliksense:
L'accés als portals web de Qlikview o Qliksense es fa a través de l'accés restringit de la Diputació (https://dibaaps.diba.cat/vus/login.asp [1]). Trobem els següents productes per accedir als respectius portals web:
- QVS_ACCES_POINT --> Accés al portal ACCES_POINT de Qlikview que correspón al portal corporatiu de difusió d'informes Qlikview.
- QVS_INFOANALISIS --> Accés al portal ACCES_POINT de Qlikview pel Qlikview Extranet Server. Correspón al portal de difusió municipal i altres ens locals d'informes Qlikview.
- QS_INFOANALISIS_PRO --> Accés al portal QlikSense de l'entorn de desenvolupament
- QS_INFOANALISIS_TEST --> Accés al portal QlikSense de l'entorn de test.
- QS_INFOANALISIS --> Accés al portal QlikSense de l'entorn de productiu.
Les bases de dades internes son Oracle versió 19.
Les connexions a la BD es fan amb un connexió ODBC, OLEDB, JDBC.
En fase de desenvolupament s'establirà una connexió contra la màquina de test (isi.world).
Cal treballar els processos ETL amb l'ús de Repositoris Pentaho.
Es defineix un repositori específic per cada projecte i s'importen en el Repositori de Productiu per la posada en marxa del projecte.
El repositori de productiu es PentahoRepository associat a una BD HSQLDB.
S'espera que s'utilitzi el framework de desenvolupament definit per la Diputació de Barcelona i que trobareu en el següent enllaç: https://comunitatdstsc.diba.cat/wiki/arquitectura-duna-solucio-pentaho [2]
S'espera que s'utilitzi l'estructura de Qlik Deployment Framework. La DSTSC crearà el projecte i llliurarà la carpeta QDF al desenvolupador.
La solució ha de ser de fàcil manteniment un cop lliurada i complir les best practices de programació:
Una projecte Qlik comporta les següents capes de codi, com a mínim:
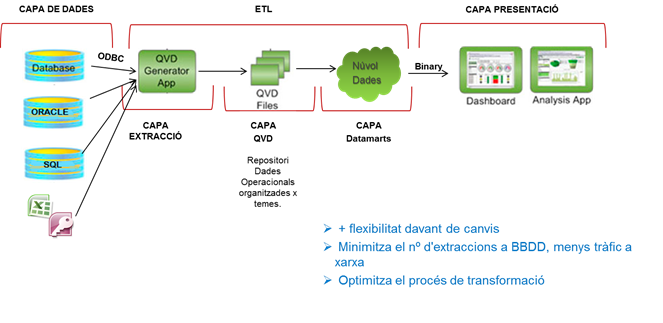
Els processos dedicats a extraure dades s'anomenaran: Extractors.
Les eines TI que actualment s’utilitzen per a fer l’extracció de dades són les següents:
Hi ha l’extractor de la capa 0 y l’ extractor de la capa 1. La nomenclatura ha de ser : Extraccio_(nomEsquema)_CapaX.qvw
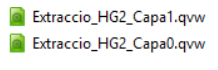
Es defineixen dos nivells d'extracció de dades:
1er nivell d'extracció implica l'extracció directa de totes les dades sense fer cap transformació.
Les dades quedaran ubicades en la carpeta Capa 0 (Stage area) en forma de fitxers QVDs. (<Proj.QDF>\1.QVD\1.Capa_0)
Si la dada es troba en la BD Oracle19, farem l'extracció amb un procés Qlik.
Si la dada es troba en una Font externa (exemple: INE, Idescat, Portal Dades Obertes Gene) s'ha de valorar amb la DSTSC, si és necessari emmagatzemar la dada en el magatzem de dades ORACLE o altre. Per aquesta gestió s’hauria d’utilitzar Pentaho Data Integrationl.
La Capa 0 ha de ser una capa de dades extretes directament de l’origen i sense cap transformació. Si es tracta d’una taula d’un SGBD el nom del QVD generat serà el de la taula extreta, si es tracta d’un fitxer el nom serà el del fitxer.
2on nivell d'extracció, equival al procés de transformació de les dades. En aquesta capa s'espera:
- Format i qualitat de les dades correcta
- Definir el Diccionari de dades dels camps (s'ha de consensuar amb l'usuari responsable del negoci)
El resultat ha de ser en forma de fitxers QVD, de tal manera que:
- Cada fitxer identifiqui la informació d'un objecte de negoci: codis, atributs i valors
- Cal documentar cada QVD generat en aquesta fase
Les dades quedaran ubicades en la carpeta Capa 1 ((<Proj.QDF>\1.QVD\1.Capa_0)) en forma de fitxers QVDs.
És obligatòri pels QVDs de la Capa 1, asignar una descripció que identifiqui el contingut del QVD. L'assignació de la descripció s'ha de fer en l'Extractor de Capa1 i de la següent forma:

Els QVDs desenvolupats es traspassaran al repositori central quan la solució es posi a producció.
Abans de generar un nou QVD per un projecte, cal identificar si ja existeix en el Repositori (DSTSC determinarà aquesta informació durant fase análisis projecte).
Es en aquest procés on s'estableixen les connexions, es defineixen les taules de FETS, Link Tables i Taules d'atributs.
La nomenclatura ha de ser.
Nom: NUVOL-XXX tal que XXX es determinarà amb la DSTSC.
Cal que les aplicacions analítiques utilitzen el full d'estils corporatius.
En el cas de Qlikview, trobareu les plantilles corporatives a (\\nas\apps\QLIK_DADES, la DSTSC gestionarà l'accés en aquesta carpeta).
En el cas de QlikSense, cal fer servir el Tema de la Diputació.
Qlikview/QlikSense:
La gestió de permisos s'ha de definir a partir del qvd's: TaulaUsuaris.qvd i PermisosUsuaris. qvd.
La gestió de permisos es farà amb secció d'accés quan aquest impliquin una reducció de la informació possible a consultar.
| Adjunt | Mida |
|---|---|
| Exemple_Fitxer_variables_mesures [4] | 26.3 KB |
Aquest document pretén explicar el model de treball per la gestió de projectes de BI.
Els projectes de BI es gestionaran utilitzant la metodologia de treball próxima a l'SCRUM.
L'aplicació Redmine serà el sistema de gestió del desenvolupament del projecte. Cal tenir en compte que Redmine es un entorn col·laboratiu que permet la gestió i seguiment de les tasques del projecte. Redmine basa la gestió de projectes en assumptes. Els assumptes poden ser de diverses tipologies: funcionalitats, tasques, errors, reunions.
Tots els membres de l'equip estaràn registrats en el projecte definit a Redmine.
Dins el projecte de Redmine hi ha una wiki on s'organitzarà de forma estructurada la documentació del projecte.
Per fer la gestió correcta del projecte en Remine, cal tenir en compte les següent consideracions:
L’acte de la reunió caldrà incorporar-la en el Redmine generant un assumpte de tipus Reunió.
El Cap de projecte de la Diputació, caldrà que doni d'alta el projecte en el Redmine especificant:
Correspon a la primera fase d’anàlisis que consisteix en un conjunt de reunions on els membres de l’equip es reuniran per revisar els requeriments d’usuari.
Les actes de les reunions caldrà actualitzar-les en el Redmine.
D’aquesta fase sorgirà un document de definició del projecte i la concretació d’un conjunt de funcionalitats a desenvolupar que defineixen el backlog del projecte.
Les funcionalitats a desenvolupar o backlog caldrà crear-les en el Redmine amb el tipus d’assumpte funcionalitat.
De cada funcionalitat es generen les tasques vinculades que cal fer amb el tipus d’assumpte tasca.
La tasca s’assignarà al responsable del seu desenvolupament.
A la tasca s’aniran afegint notes per documentar la seva situació i les especificitats del seu desenvolupament.
Les tasques es re-assignaran a altres responsables, en el cas que sigui necessari.
La tasca, tindrà un cicle de vida determinada per les següents fases:
Cal que el responsable de desenvolupar una tasca de Redmine assigni el temps que hi ha dedicat.
Cal que a la factura hi consti, només les funcionalitats o tasques tancades.
Cal que el temps total, dedicat a cada funcionalitat o tasca conicideixi amb el temps de dedicació mecanitzat al Redmine.
Pentaho Data Integration, es l'alicació ETL que ens permet extraure la informació de les fonts de dades (preferiblement APIs), transformar-les en el format requerit i carregar-les al magatzem de dades de la organització (BD Oracle, esquema MG02).
Actualment podem dir que disposem de com a mínim 4 magatzems de dades en Oracle: HG2, MG01, MG02, MG03.
Un projecte de Pentaho consisteix en l'elaboració de processos de transformació que gestionen l'extracció de dades des de una font origen y la inserció de les dades en una fotn destí. En el nostre cas les fonts origen poden ser API's habilitades a través de Internet, fitxers locals que l'usuari pot preparar i contingut de pàgines web. De la mateixa manera podem dir que les fonts destí són o bé fitxers de sortida majoritàriament en format .csv o d'altres, o bé la Base de Dades Oracle o Mongo DB.
Els processos de ETL de Pentaho es consisteixen en processos de transformació (.ktr) i processos jobs (.kjb).
La diferència bàsica entre un job i una transformació, és que el job determina l'ordre d'execució de les transformacions. Les transformacions són les que gestiones el processament dels registres que s'extrauen, es transformes i es guarden.
Un procés d'extracció d'un dataset està format per:
El conjunt de processos Pentaho actius de la corporació han de residir en el repositori de productiu, anomenat PentahoRepositori. Actualment aquest repositori es gestiona sobre una base de dades hsqldb que és la que ve per defecte amb la instal·lació de Pentaho Server.
El Pentaho Server està instal·lat en el servidor sw0301.
L'entrada de dades dels processos estarà ubicada en URIs o seran fitxers ubicats en carpetes del servidor d'aplicacions NAS, on els Serveis encarregats de gestionar les dades disposaran d'un conjunt de carpetes que seguiran una definició estandarditzada. En aquesta estructura de carpetes també pot haver-hi espais on els processos dels servidor poden generar els possibles fitxers de sortida.
Estructura de carpetes per extracció d'un Dataset [5]
Estructura de les dades d’entrada [6]
Taules de control de la Base de Dades [7]
Veurem l'estructura de carpetes que organitzen els processos ETL que alimenten un repositori de dades concret, per exemple MG02 que és el repositori generat pel projecte de Canvi Climàtic (QV_CANVI_CLIMATIC):

A continuació expliquem l'estructura, els seus nivells i una breu descripció:
(Configuració variables del sistema) [8]
[Nom Repositori]
00.Configuracio (Configuració global del projecte canvi climàtic) [9]
01.Jobs (Jobs globals, que es fan servir en totes o varies fonts.) [10]
02.Transformacions
03.Font [nom_procés]
00.Configuracio: Conté el fitxer config.properties, és el fitxer de configuració de variables locals [11], és a dir únics de el procés [nom_procés].
01.Jobs: Conté els jobs del procés [nom_procés] (Variables definides a nivell de job.) [12]
02.Transformacions: Conté les transformacions del procés [nom_procés]01.Subtransformacions: Si aplica, conté llavors les transformacions que es fan servir dins d'una altra transformació del procés [nom_procés].
05.Output:
00.Configuracio: Conté el fitxer config.properties, és el fitxer de configuració de variables locals, és a dir únics de el procés 05.Output.
01.Jobs: Conté els jobs del procés 05.Output.
02.Transformacions: Conté les transformacions del procés 05.Output.01.Subtransformacions: Conté les transformacions que es fan servir dins d'una altra transformació del procés 05.Output.
L'estructura dels fitxers d'entrada estarà ubicada a la carpeta departamental del Servei encarregat de emmagatzematge de les dades del repositori.

A continuació expliquem l'estructura, els seus nivells i una breu descripció
03.Font [nom procés]: Nom del procés.
03. Fitxers d’entrada: En aquesta carpeta s'ha d'ubicar el fitxer d'entrada.
Processats: Quan el fitxer s'ha processat es mou a aquesta subcarpeta
Enllaços:
[1] https://dibaaps.diba.cat/vus/login.asp
[2] https://comunitatdstsc.diba.cat/wiki/arquitectura-duna-solucio-pentaho
[3] https://comunitatdstsc.diba.cat/sites/comunitatdstsc.diba.cat/files/userfiles/comunitat/ods.variables.xlsx
[4] https://comunitatdstsc.diba.cat/sites/comunitatdstsc.diba.cat/files/ods.variables.xlsx
[5] https://comunitatdstsc.diba.cat/wiki/estructura-de-carpetes-per-extraccio-dun-dataset
[6] https://comunitatdstsc.diba.cat/wiki/estructura-de-les-dades-d-entrada
[7] https://comunitatdstsc.diba.cat/wiki/taules-de-control-de-base-de-dades
[8] https://gestioprojectes.diba.cat/projects/qv_canvi_climatic/wiki/(Configuraci%C3%B3_variables_del_sistema)
[9] https://gestioprojectes.diba.cat/projects/qv_canvi_climatic/wiki/(Configuraci%C3%B3_global_del_projecte_canvi_clim%C3%A0tic)
[10] https://gestioprojectes.diba.cat/projects/qv_canvi_climatic/wiki/(Jobs_globals_que_es_fan_servir_en_totes_o_varies_fonts)
[11] https://gestioprojectes.diba.cat/projects/qv_canvi_climatic/wiki/Fitxer_de_configuraci%C3%B3_de_variables_locals
[12] https://gestioprojectes.diba.cat/projects/qv_canvi_climatic/wiki/(Variables_definides_a_nivell_de_job)
[13] https://gestioprojectes.diba.cat/attachments/22214
[14] https://gestioprojectes.diba.cat/attachments/22215